Kvartiler och lådagram
I det förra avsnittet om lägesmått använde vi oss av ett exempel med en släktmiddag som familjen Mattecentrum anordnade. Åldrarna på de närvarande personerna vid släktmiddagen var
$$1,\, 4,\, 3,\, 15,\, 72,\, 41,\, 30,\, 27,\, 72,\, 8,\, 42,\, 36,\, 33,\, 46,\, 44$$
En person som inte var med på släktmiddagen var Mattias, som istället var på middag med ett antal vänner. Åldern på de 15 personer som var med vid Mattias middag var som följer:
$$30,\, 31,\, 33,\, 34,\, 35,\, 34,\, 28,\, 34,\, 33,\, 34,\, 36,\, 35,\, 32,\, 31,\, 32$$
Vi jämför lägesmåtten vad gäller åldern på personerna i dessa båda grupper. Då ser vi att medelvärdet och medianen för släktmiddagen är
$$medel=31,6 \,år$$
$$median=33 \,år$$
För personerna som deltog vid kompismiddagen blir lägesmåtten följande:
$$medel=32,8\,år$$
$$median=33\,år$$
Tittar vi bara på dessa lägesmått så ser det inte ut som att det var så stor skillnad mellan åldrarna vid de två tillställningarna, utom möjligtvis att gruppen som närvarade vid kompismiddagen verkar aningen äldre om man jämför medelvärdena. Vi som dock har sett åldrarna som förekommer i de två grupperna vet att det är stor skillnad på spridningen av åldrarna mellan de två grupperna - vid släktmiddagen är spridningen stor, medan spridningen vid kompismiddagen är mindre.
För att kunna jämföra två eller flera serier av observationsvärden har man därför infört olika spridningsmått. Genom dessa kan man få en mer rättvisande bild av hur olika serier av värden ser ut och hur stor spridningen är i de olika serierna. I det här avsnittet ska vi därför gå igenom begreppen variationsbredd, kvartiler och lådagram, för att i nästa avsnitt titta närmare på standardavvikelse som ett mått på hur mycket värden avviker från medelvärdet i en serie.
Variationsbredd
Ett enkelt mått på spridning i en serie observationsvärden är variationsbredd, som definieras som skillnaden (differensen) mellan det största och det minsta observationsvärdet i serien.
I vårt exempel med släktmiddagen får vi variationsbredden vad gäller ålder genom att subtrahera den högsta förekommande åldern (72 år) och den lägsta (1 år)
Det vill säga
$$72-1=71\, år$$
På samma sätt beräknar vi variationsbredden vad gäller ålder vid kompismiddagen, där den högsta åldern var 36 år och den lägsta 28 år. Vi får i detta fall variationsbredden
$$36-28=8\, år$$
Som vi ser så får vi väldigt olika värden på variationsbredden i de båda grupperna, vilket ju beror på att åldersspridningen är mycket större vid släktmiddagen än vid kompismiddagen.
Variationsbredden är alltså mycket enkel att räkna ut, men detta mått har nackdelen att det inte tar hänsyn till alla observationsvärdena, utan enbart det största och det minsta värdet. För att få en bättre bild av spridningen använder man därför även andra spridningsmått.
Kvartiler
Ett bättre sätt att beskriva spridningen runt medianen är att dela in observationsvärdena i kvartiler. Kvartil betyder fjärdedel och dessa kvartiler kommer vi fram till genom att dela in våra storlekssorterade observationsvärden i fyra lika stora grupper.
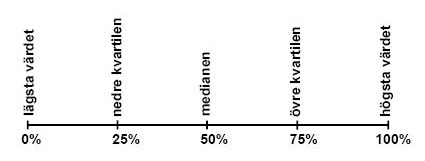
Det finns fem viktiga värden att hålla koll på när vi ska dela in våra observationsvärden i kvartiler:
Det högsta värdet och det lägsta värdet, som är de mest extrema observationsvärdena vi har åt vardera hållet i serien. Dessa motsvarar alltså det största och det minsta värdet som vi använde då vi räknade ut variationsbredden tidigare i avsnittet.
Vi behöver även känna till medianen, som ju delar våra storlekssorterade observationsvärden i två lika stora delar.
De två sista värdena som vi måste ta reda på är den nedre kvartilen, som delar de lägre 50 % av värdena i två lika stora delar, och den övre kvartilen, som delar upp de högre 50 % av värdena i två lika stora delar. Detta innebär att 25 % av våra observationsvärden kommer att vara mindre än den nedre kvartilen och 75 % av observationsvärdena kommer att vara mindre än den övre kvartilen.
Ofta betecknar man den nedre kvartilen som Q1, medianen som Q2 och den övre kvartilen som Q3.
Vi visar hur dessa viktiga värden förhåller sig till observationsvärdena i figuren nedan.
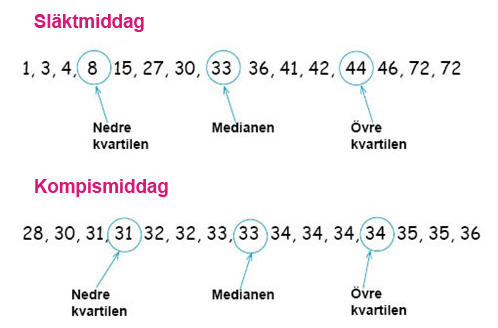
När vi nu har gått igenom definitionerna av dessa begrepp kan vi beräkna dessa fem värden för våra två middagssällskap
Skillnaden mellan den övre och den nedre kvartilen kallas för kvartilavståndet. Detta motsvarar variationsbredden för de 50 % av värdena som befinner sig i mitten av serien av observationsvärden. Därigenom är kvartilavståndet ett mått på hur stor spridningen är i närheten av medianen.
Kvartilavståndet för deltagarnas ålder vid släktmiddagen får vi genom denna definition till
$$44-8= 36\, år $$
På motsvarande sätt beräknar vi kvartilavståndet för deltagarnas ålder vid kompismiddagen till
$$34-31=3\, år$$
Lådagram
Med hjälp av de begrepp rörande kvartiler som vi har introducerat ovan kan vi åskådliggöra spridningen runt medianen med hjälp av lådagram.
Ett lådagram ritas på en tallinje och består av en låda (rektangel) vars vänstra respektive högra sida befinner sig vid den nedre respektive den övre kvartilen. Observationsvärdenas medianvärde är även markerat med en vertikal linje inuti lådagrammet. Från lådans respektive sidor sträcker sig en vågrät linje ut till det största respektive lägsta observationsvärdet i serien.
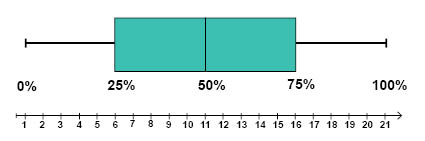
Nedan har vi ritat ett lådagram för värden i intervallet 1 (lägsta värdet) till och med 21 (högsta värdet). I detta exempel är medianen 11, nedre kvartilen 6 och övre kvartilen 16.
På motsvarande sätt kan vi presentera observationsvärdena från vår undersökning av åldern på deltagarna vid släktmiddagen respektive kompismiddagen med hjälp av följande två lådagram:
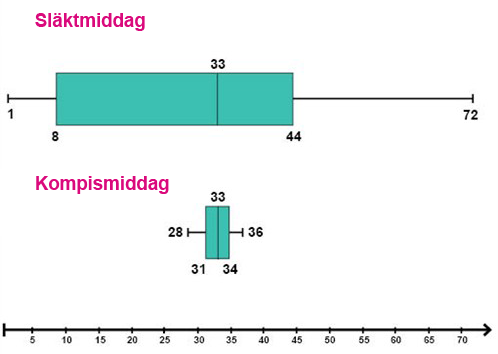
Nu kan vi tydligt se att även om deltagarna vid de båda middagarna hade samma medianålder (33 år) så är det stor skillnad i spridningen av åldrar.
Percentiler
På motsvarande sätt som man kan dela upp observationsvärden i fjärdedelar (kvartiler) kan man även dela upp stora serier av observationsvärden i hundradelar. Gör man en uppdelning i hundradelar benämner man dessa hundradelar som percentiler.
Specifika percentiler benämner man på ett liknande sätt som kvartiler. Till exempel motsvarar den nedre kvartilen, Q1, den 25:e percentilen, som vi betecknar P25 (alltså att 25 % av observationsvärdena ska vara mindre än detta värde). På motsvarande sätt kan man beteckna medianen som P50 och övre kvartilen som P75.
Eftersom vårt observationsmaterial från de båda middagarna är så pass litet (15 observationsvärden i vardera fallet) är det mer lämpligt att använda sig av kvartiler än percentiler. Hade vi haft en serie bestående av ett större antal observationsvärden, till exempel om man gjorde en undersökning av åldern bland tusen människor, då hade användning av percentiler kunnat vara mer användbar.
I nästa avsnitt ska vi fortsätta att undersöka hur man kan ange spridningen i serier av observationsvärden, genom användning av måttet standardavvikelse.
Här går vi igenom hur ett lådagram konstrueras.
Här går vi igenom hur ett lådagram konstrueras.
Här går vi igenom spridningsmåtten variationsbredd och kvartilavstånd.
Här går vi igenom spridningsmåtten variationsbredd och kvartilavstånd.
Här går vi igenom hur ett lådagram konstueras.
- Observationer: de mätningar, iakttagelser eller resultat vi får från en undersökning
- Spridningsmått: mått på utspridningen av observationer
- Variationsbredd: Skillnaden på högsta och minsta värde.
- Median om vi sorterar alla våra observationer i storleksordning så är det värde som hamnar i mitten medianen.
- Kvartiler: de tre bitar som observationerna delas in i för att skapa fyra lika stora delar. Första kvartilen, \(Q_1\) motsvarar det första 25% av observationerna, Andra kvartilen \(Q_2\) är medianen och tredje kvartilen \(Q_3\) markerar 75% av observationerna.
- Lådagram: Ett diagram som visar upp spridningsmåttet för sorterade observationer. Lådan går från \(Q_1\) till \(Q_3\) med \(Q_2\) markerat och innehåller 50% av observationerna. Sedan sträcker sig en linje ut till högsta och minsta värde och vi kan därför hitta variationsbredden. Ett lådagram ser ut så här:
- Percentiler: Ett annat sett att beskriva observationerna men uppdelat i procent. Betecknas ofta \(P_i\) för att markera vilken procent, därför är \(P_25 = Q_1\) och \(P_50= Q_2\), dvs medianen.